Note
Go to the end to download the full example code.
Calculation of revenues¶
We use an estimated model to calculate revenues.
Michel Bierlaire, EPFL Sat Jun 28 2025, 18:57:49
import sys
import numpy as np
from biogeme.biogeme import BIOGEME
from biogeme.models import nested
from biogeme.results_processing import EstimationResults
try:
import matplotlib.pyplot as plt
can_plot = True
except ModuleNotFoundError:
can_plot = False
from biogeme.data.optima import read_data, normalized_weight
from scenarios import scenario
Read the estimation results from the file.
try:
results = EstimationResults.from_yaml_file(
filename='saved_results/b02estimation.yaml'
)
except FileNotFoundError:
sys.exit(
'Run first the script b02simulation.py '
'in order to generate the '
'file b02estimation.yaml.'
)
Read the data
database = read_data()
Function calculating the revenues
def revenues(factor: float) -> tuple[float, float, float]:
"""Calculate the total revenues generated by public transportation,
when the price is multiplied by a factor.
:param factor: factor that multiplies the current cost of public
transportation
:return: total revenues, followed by the lower and upper bound of
the confidence interval.
"""
filename = f'revenue_{factor:.2f}.txt'
SEPARATOR = '%'
try:
with open(filename, 'r') as f:
line = f.read()
revenue, left, right = line.split(SEPARATOR)
return float(revenue), float(left), float(right)
except FileNotFoundError:
...
# Obtain the specification for the default scenario
utilities, nests, _, marginal_cost_scenario = scenario(factor=factor)
# Obtain the expression for the choice probability of each alternative
prob_pt = nested(utilities, None, nests, 0)
# We now simulate the choice probabilities,the weight and the
# price variable
simulate = {
'weight': normalized_weight,
'Revenue public transportation': prob_pt * marginal_cost_scenario,
}
the_biogeme = BIOGEME(database, simulate)
simulated_values = the_biogeme.simulate(results.get_beta_values())
# We also calculate confidence intervals for the calculated quantities
beta_bootstrap = results.get_betas_for_sensitivity_analysis()
left, right = the_biogeme.confidence_intervals(beta_bootstrap, 0.9)
revenues_pt = (
simulated_values['Revenue public transportation'] * simulated_values['weight']
).sum()
revenues_pt_left = (left['Revenue public transportation'] * left['weight']).sum()
revenues_pt_right = (right['Revenue public transportation'] * right['weight']).sum()
with open(filename, 'w') as f:
print(
f'{revenues_pt} {SEPARATOR} {revenues_pt_left} {SEPARATOR} {revenues_pt_right}',
file=f,
)
return revenues_pt, revenues_pt_left, revenues_pt_right
Current revenues for public transportation
r, r_left, r_right = revenues(factor=1.0)
print(
f'Total revenues for public transportation (for the sample): {r:.1f} CHF '
f'[{r_left:.1f} CHF, '
f'{r_right:.1f} CHF]'
)
Total revenues for public transportation (for the sample): 3043.3 CHF [2527.9 CHF, 3729.4 CHF]
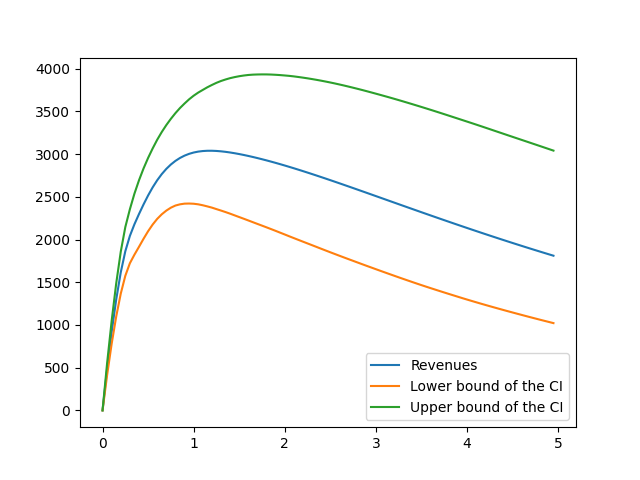
We now investigate how the revenues vary with the multiplicative factor
factors = np.arange(0.0, 5.0, 0.1)
plot_revenues = [revenues(s) for s in factors]
zipped = zip(*plot_revenues)
rev = next(zipped)
lower = next(zipped)
upper = next(zipped)
largest_revenue = max(rev)
max_index = rev.index(largest_revenue)
print(
f'Largest revenue: {largest_revenue:.1f} obtained with '
f'factor {factors[max_index]:.1f}'
)
Largest revenue: 3062.3 obtained with factor 1.2
if can_plot:
# We plot the results
ax = plt.gca()
ax.plot(factors, rev, label="Revenues")
ax.plot(factors, lower, label="Lower bound of the CI")
ax.plot(factors, upper, label="Upper bound of the CI")
ax.legend()
plt.show()
Total running time of the script: (0 minutes 2.216 seconds)